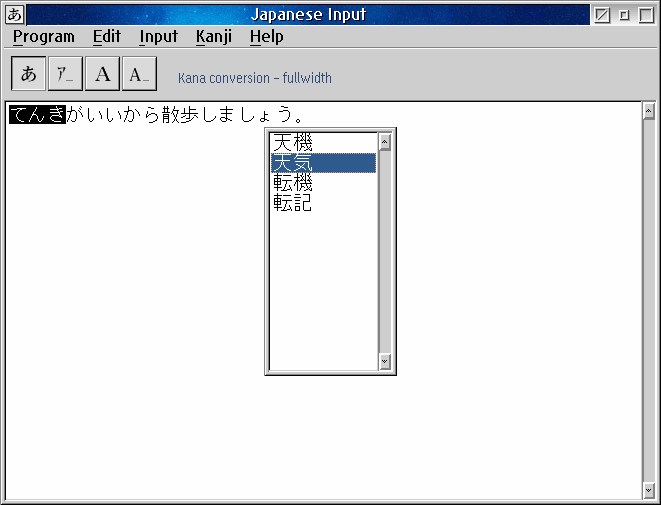
On Fri, 29 Mar 2019 19:44:57 +0900 ishikawa wrote: > > https://bugzilla.mozilla.org/show_bug.cgi?id=1525867 > https://bug1525867.bmoattachments.org/attachment.cgi?id=9049748 > https://bug1525867.bmoattachments.org/attachment.cgi?id=9049748 > > These are the attachments from the original bug entry. > > I needed to create these screen dumps in order to explain the > misbehavior of kinput2-wnn Japanese input with firefox and thunderbird. > (The problem was fixed, and I am waiting for the official release in May > time frame.) Interesting. I understand better how the user experience works now. I'd like to support changing individual parts of the clause like this. Before, I was puzzled by the difference in FreeWnn's two different conversion function: "jl_ren_conv()" and "jl_tan_conv()". I think I understand it more now. It seems that jl_tan_conv() works to convert single word-phases only, whereas jl_ren_conv() works on an entire clause. For example, take the sample clause "わたしのなまえはなかのです。" Calling jl_ren_conv() with this sentence returns these candidates: 1) わたしの名前は中野です 2) 渡しの名前は中野です。 3) 渡しの名前は中野です。 4) ワタシの名前は中野です 5) ワタシノ名前は中野です 6) わたしの名前は中野です 7) 私の名前は中野です。 Calling jl_tan_conv() with the same sentence produces only: 1) ワタシノナマエハナカノデス 2) わたしのなまえはなかのです 3) ワタシノナマエハナカノです This puzzled me until I discovered that jl_tan_conv() only works if I split the sentence into small pieces. So passing it only "わたしの" returns: 1) わたしの 2) 渡しの 3) 渡しの 4) ワタシの 5) ワタシノ 6) わたしの 7) 私の Then passing "なまえは" gives me: 1) ナマエは 2) ナマエハ 3) なまえは 4) 名前は and so on. Obviously this function is designed to be used like how you described in the screen shots: one word (or word-phrase) at a time. Unfortunately, so far I don't know how to split the sentence up into individual word phrases automatically. Maybe I will have to require the user to just highlight the portion they want to convert, themselves... Hmm... actually, maybe I could call jl_ren_conv() first, then identify all the pieces (among the candidates) which are different, using string parsing. That might work... > It is always a pleasure to help someone use Wnn server and related > tools. It would keep the ecosystem alive and will benefit me as well. > Very selfish reason :-) :) I'm having fun learning this stuff. Even if no-one but me uses this program. > PS: Hmm, come to think of it, Japanese version of OS/2 used to come with > a Japanese input front end developed by IBM Japan, I think. However, > I threw away all the OS/2 related magazines, etc. a few years back. > The graphical interface worked in a similar manner by highlighting the > conversion target somehow. I have the Japanese version of OS/2 as well (on a test system). But I don't use it for my usual work because the entire OS is in Japanese, and also it doesn't let me use English keyboard layout or do some other things like that. The OS/2 IME is certainly useful, although I think it's primitive compared to other IMEs nowadays. Unfortunately, it's tied to the Japanese OS/2 and I can't use it on the English OS. Until now I've been using a different method to type Japanese on my English OS/2 system. I wrote a simple IME which lets me type into its window and then copy-paste the Japanese text to another program: http://www.altsan.org/programming/os2/imerj01.png But it can only convert dictionary words, and you have to select the kana manually after typing them. This is tedious compared to a proper IME, so I want to write this FreeWnn based IME for myself to use. If other people find it useful, that's a bonus. :) Thanks, Alex -- Alex Taylor <alex****@altsa*****> http://www.altsan.org

{kind=link}